Written by Daniel Rutschmann. Translated by Daniel Rutschmann.
This article covers an advanced technique know as the “Alien trick”. The name originates from the task “Aliens” from IOI 2016, the task that made this technique popular. Other less popular names for this technique are “WQS/WPS binary search” or “Lagrange optimization”.
This article assumes that the reader is familiar with dynamic programming, greedy and scanline ideas. After all, you first need to come up with a correct solution before you can optimize it.
Suppose we are solving some minimization problem where we have some parameter that we need to keep in our state. Common examples of this are:
- Splitting an array into exactly parts.
- Picking exactly elements / edges / ranges.
- Picking at most elements, but picking more elements is never worse.
In many cases, this parameter has to be kept as an additional dimension in our dp state, making our solution slower by a factor of . For instance, our solution might run in , but if we didn’t care about , we could get a solution with a runtime of instead. The Alien trick allows you to get rid of the parameter under some convexity assumptions.
The Technique
For some minimization problem with some parameter , let denote the answer. A good example to think of is “minimal cost of splitting an array into parts”. To solve task, we want to compute the answer for some fixed , i.e. we want to compute . Often, this is much more difficult than computing (i.e. solving the problem without caring about the parameter ).
The alien trick applies to the case where is convex.
A function is convex if
Some examples of convex functions are or .
Instead of computing , the alien trick fixes some and computes
i.e. it doesn’t require the solution to have a correct values of , but it helps (if ) or penalizes (if ) solutions that have a large value of . Let denote the optimal value of for a certain , i.e.
In our example, this would correspond to the number blocks we would use if every block has a cost of . The key observation is the following:
If is convex, then is non-descreasing. In other words, higher values of will lead to higher values of .
This property allows us to binary search for to find a solution for which . This allows us to replace the factor in the runtime with a log-factor from the binary search.
Intuition behind the Technique
Let be a convex function. If we plot a convex function, the graph looks like the bottom half of a convex polygon
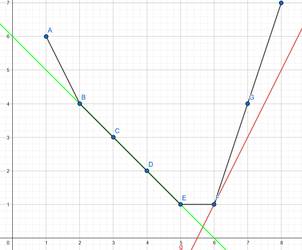
Computing corresponds to finding a lower tangent with slope to this graph / polygon.
We can also see this mathematically. As is the optimial , we have
i.e.
Similarly, we have
i.e.
The two equations
tell us that the “slope” to the left of is at most and the “slope” to the right of is at least . Hence the line with slope at is a tangent.
As is convex, the “slope” is non-decrasing in , hence higher values of will lead to higher values of .
Degeneracy
TODO
For (2), just interpolate linearly between the integer values of f. This will look something like this
Our interpolated function has corners, but we can still find the point (or segment in the case of the green line) where a line with slope touches . Once again, increasing the slope of the line will make us find points further to the right, so we can binary search for . The green line covers the one corner case we have to handle: If we’re looking for point or (i.e. or ), then we might only find and (i.e. we skip from to ). In the picture, we see that in this case we just linearly interpolate between and .
Implementation
To efficiently implement the Alien trick, we want to do everything with integers. Hence we will only use .